








场景:join时的过滤条件下推
需求:快速查看sql结果的schema,用于平台可视化配置
判断标识:explain sql语句看table scan时的stage的predicate是否有内容
开关:hive2的cbo,hive1的ppd
用途:提升sql性能&节约开销、查询复杂语句的结果集schema
先说结论:hiveserver2的谓词下推作用十分有限。
测试环境:hive3.1.2
explain select
`a`.`member_card_id` as `member_id`
,`a`.`full_name` as `member_name`
,`a`.`mobile` as `mobile`
,`a`.`card_no` as `card_no`
,`a`.`grade` as `grade`
,`a`.`grade_begin_date` as `grade_begin_date`
,`a`.`grade_date` as `grade_date`
,`a`.`store_code` as `reg_store_code`
,`a`.`reg_time` as `reg_time`
,datediff( current_date ,`a`.`reg_time` ) as `reg_time_length`
,case when YEAR(`a`.`reg_time`) = YEAR( date_sub(current_date ,1 ) ) then 1 else 0 end as `new_flag`
,`a`.`birthday` as `birthday`
,`a`.`gender` as `gender`
,case when extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`birthday`)>=0
then extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`birthday`)
else '未知' end as `age` --datediff( date_sub(current_date ,1 ) ,a.birthday )
,`a`.`marriage_flag` as `marriage_flag`
,case when `a`.`marriage_flag` = 0 then '未婚'
when `a`.`marriage_flag` = 1 then '已婚'
else '未知'
end as `marriage_desc`
,`a`.`subbrand_flag` as `subbrand_flag`
,`a`.`province` as `province`
,`a`.`city` as `city`
,`a`.`area` as `area`
,`a`.`guide_code` as `guide_code`
,`a`.`blacklist_type_flag` as `blacklist_type_flag`
,`a`.`blacklist_time` as `blacklist_time`
,`a`.`baby_birthday` as `baby_birthday`
,`a`.`baby_gender` as `baby_gender`
,`a`.`second_baby_birthday` as `second_baby_birthday`
,`a`.`second_bady_gender` as `second_bady_gender`
,`a`.`third_bady_birthday` as `third_bady_birthday`
,`a`.`third_bady_gender` as `third_bady_gender`
,`a`.`ori_member_id` as `ori_member_id`
,`a`.`status_flag` as `status_flag`
,case when extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`birthday`)>=0 and extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`birthday`)<18 then '18岁以下'
when extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`birthday`)>=18 and extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`birthday`)<26 then '18-25岁'
when extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`birthday`)>=26 and extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`birthday`)<31 then '26-30岁'
when extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`birthday`)>=31 and extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`birthday`)<36 then '31-35岁'
when extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`birthday`)>=36 and extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`birthday`)<41 then '36-40岁'
when extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`birthday`)>=41 and extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`birthday`)<46 then '41-45岁'
when extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`birthday`)>=46 and extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`birthday`)<51 then '46-50岁'
when extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`birthday`)>=51 and extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`birthday`)<999 then '50岁以上'
else '未知'
end as `age_group`
,case when extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`baby_birthday`)>=0 and extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`baby_birthday` )<2 then '0-1岁'
when extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`baby_birthday`)>=2 and extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`baby_birthday` )<4 then '2-3岁'
when extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`baby_birthday`)>=4 and extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`baby_birthday` )<7 then '4-6岁'
when extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`baby_birthday`)>=7 and extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`baby_birthday` )<11 then '7-10岁'
when extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`baby_birthday`)>=11 and extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`baby_birthday` )<16 then '11-15岁'
when extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`baby_birthday`)>=16 and extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`baby_birthday` )<19 then '16-18岁'
when extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`baby_birthday`)>=19 and extract(year from date_sub(current_date ,1 )) - extract(year from `a`.`baby_birthday` )<91 then '大于18岁'
else '未知'
end as `child_age_group`
,case when YEAR(`a`.`reg_time`) = YEAR( date_sub(current_date ,1 ) ) then '新客' else '老客' end as `new_flag_desc`
,`a`.`dt` as `dt`
from `bi_dw`.`f_ip_hy_member_card_s` `a`
left join `bi_ods`.`o_my_ncm_grade_detail_f` `b`
on `a`.`grade` = `b`.`grade_level`
-- and `b`.`dt` = date_sub(scurrent_date ,1 )
-- and `b`.`brand_id` = '1100'
-- where `a`.`dt` = date_sub(current_date ,1 ) and 1=2 limit 1
where `a`.`dt`='2022-07-31' and 1=2 limit 1结果
STAGE DEPENDENCIES:
Stage-4 is a root stage
Stage-3 depends on stages: Stage-4
Stage-0 depends on stages: Stage-3
STAGE PLANS:
Stage: Stage-4
Map Reduce Local Work
Alias -> Map Local Tables:
$hdt$_1:b
Fetch Operator
limit: -1
Alias -> Map Local Operator Tree:
$hdt$_1:b
TableScan
alias: b
Statistics: Num rows: 8492 Data size: 6884400 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: grade_level (type: int)
outputColumnNames: _col0
Statistics: Num rows: 8492 Data size: 6884400 Basic stats: COMPLETE Column stats: NONE
HashTable Sink Operator
keys:
0 _col3 (type: int)
1 _col0 (type: int)
Stage: Stage-3
Map Reduce
Map Operator Tree:
TableScan
alias: a
Statistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONE
Filter Operator
predicate: false (type: boolean)
Statistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONE
Select Operator
expressions: member_card_id (type: bigint), mobile (type: string), card_no (type: string), grade (type: int), grade_begin_date (type: timestamp), grade_date (type: timestamp), store_code (type: string), status_flag (type: int), blacklist_type_flag (type: int), blacklist_time (type: timestamp), reg_time (type: timestamp), baby_birthday (type: string), baby_gender (type: int), second_baby_birthday (type: string), second_bady_gender (type: int), third_bady_birthday (type: string), third_bady_gender (type: int), guide_code (type: string), ori_member_id (type: string), full_name (type: string), gender (type: int), marriage_flag (type: int), birthday (type: date), subbrand_flag (type: int), province (type: string), city (type: string), area (type: string), dt (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col7, _col8, _col9, _col10, _col11, _col12, _col13, _col14, _col15, _col16, _col17, _col18, _col19, _col20, _col21, _col22, _col23, _col24, _col25, _col26, _col27
Statistics: Num rows: 1 Data size: 0 Basic stats: PARTIAL Column stats: NONE
Map Join Operator
condition map:
Left Outer Join 0 to 1
keys:
0 _col3 (type: int)
1 _col0 (type: int)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col7, _col8, _col9, _col10, _col11, _col12, _col13, _col14, _col15, _col16, _col17, _col18, _col19, _col20, _col21, _col22, _col23, _col24, _col25, _col26, _col27
Statistics: Num rows: 9341 Data size: 7572840 Basic stats: PARTIAL Column stats: NONE
Select Operator
expressions: _col0 (type: bigint), _col19 (type: string), _col1 (type: string), _col2 (type: string), _col3 (type: int), _col4 (type: timestamp), _col5 (type: timestamp), _col6 (type: string), _col10 (type: timestamp), datediff(DATE'2022-08-01', _col10) (type: int), CASE WHEN ((year(_col10) = 2022)) THEN (1) ELSE (0) END (type: int), _col22 (type: date), _col20 (type: int), CASE WHEN (((2022 - year(_col22)) >= 0)) THEN ((2022 - year(_col22))) ELSE ('未知') END (type: string), _col21 (type: int), CASE WHEN ((_col21 = 0)) THEN ('未婚') WHEN ((_col21 = 1)) THEN ('已婚') ELSE ('未知') END (type: string), _col23 (type: int), _col24 (type: string), _col25 (type: string), _col26 (type: string), _col17 (type: string), _col8 (type: int), _col9 (type: timestamp), _col11 (type: string), _col12 (type: int), _col13 (type: string), _col14 (type: int), _col15 (type: string), _col16 (type: int), _col18 (type: string), _col7 (type: int), CASE WHEN ((((2022 - year(_col22)) >= 0) and ((2022 - year(_col22)) < 18))) THEN ('18岁以下') WHEN ((((2022 - year(_col22)) >= 18) and ((2022 - year(_col22)) < 26))) THEN ('18-25岁') WHEN ((((2022 - year(_col22)) >= 26) and ((2022 - year(_col22)) < 31))) THEN ('26-30岁') WHEN ((((2022 - year(_col22)) >= 31) and ((2022 - year(_col22)) < 36))) THEN ('31-35岁') WHEN ((((2022 - year(_col22)) >= 36) and ((2022 - year(_col22)) < 41))) THEN ('36-40岁') WHEN ((((2022 - year(_col22)) >= 41) and ((2022 - year(_col22)) < 46))) THEN ('41-45岁') WHEN ((((2022 - year(_col22)) >= 46) and ((2022 - year(_col22)) < 51))) THEN ('46-50岁') WHEN ((((2022 - year(_col22)) >= 51) and ((2022 - year(_col22)) < 999))) THEN ('50岁以上') ELSE ('未知') END (type: string), CASE WHEN ((((2022 - year(CAST( _col11 AS DATE))) >= 0) and ((2022 - year(CAST( _col11 AS DATE))) < 2))) THEN ('0-1岁') WHEN ((((2022 - year(CAST( _col11 AS DATE))) >= 2) and ((2022 - year(CAST( _col11 AS DATE))) < 4))) THEN ('2-3岁') WHEN ((((2022 - year(CAST( _col11 AS DATE))) >= 4) and ((2022 - year(CAST( _col11 AS DATE))) < 7))) THEN ('4-6岁') WHEN ((((2022 - year(CAST( _col11 AS DATE))) >= 7) and ((2022 - year(CAST( _col11 AS DATE))) < 11))) THEN ('7-10岁') WHEN ((((2022 - year(CAST( _col11 AS DATE))) >= 11) and ((2022 - year(CAST( _col11 AS DATE))) < 16))) THEN ('11-15岁') WHEN ((((2022 - year(CAST( _col11 AS DATE))) >= 16) and ((2022 - year(CAST( _col11 AS DATE))) < 19))) THEN ('16-18岁') WHEN ((((2022 - year(CAST( _col11 AS DATE))) >= 19) and ((2022 - year(CAST( _col11 AS DATE))) < 91))) THEN ('大于18岁') ELSE ('未知') END (type: string), CASE WHEN ((year(_col10) = 2022)) THEN ('新客') ELSE ('老客') END (type: string), _col27 (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col7, _col8, _col9, _col10, _col11, _col12, _col13, _col14, _col15, _col16, _col17, _col18, _col19, _col20, _col21, _col22, _col23, _col24, _col25, _col26, _col27, _col28, _col29, _col30, _col31, _col32, _col33, _col34
Statistics: Num rows: 9341 Data size: 7572840 Basic stats: PARTIAL Column stats: NONE
Limit
Number of rows: 1
Statistics: Num rows: 1 Data size: 810 Basic stats: PARTIAL Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 1 Data size: 810 Basic stats: PARTIAL Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Execution mode: vectorized
Local Work:
Map Reduce Local Work
Stage: Stage-0
Fetch Operator
limit: 1
Processor Tree:
ListSink当把1=2,改成某字段=2,发生了谓词下推
STAGE DEPENDENCIES:
Stage-4 is a root stage
Stage-3 depends on stages: Stage-4
Stage-0 depends on stages: Stage-3
STAGE PLANS:
Stage: Stage-4
Map Reduce Local Work
Alias -> Map Local Tables:
$hdt$_1:b
Fetch Operator
limit: -1
Alias -> Map Local Operator Tree:
$hdt$_1:b
TableScan
alias: b
Statistics: Num rows: 8492 Data size: 6884400 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: grade_level (type: int)
outputColumnNames: _col0
Statistics: Num rows: 8492 Data size: 6884400 Basic stats: COMPLETE Column stats: NONE
HashTable Sink Operator
keys:
0 _col4 (type: int)
1 _col0 (type: int)
Stage: Stage-3
Map Reduce
Map Operator Tree:
TableScan
alias: a
Statistics: Num rows: 9786571 Data size: 42434573130 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: (one_id = 2L) (type: boolean)
Statistics: Num rows: 4893285 Data size: 21217284396 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: member_card_id (type: bigint), mobile (type: string), card_no (type: string), grade (type: int), grade_begin_date (type: timestamp), grade_date (type: timestamp), store_code (type: string), status_flag (type: int), blacklist_type_flag (type: int), blacklist_time (type: timestamp), reg_time (type: timestamp), baby_birthday (type: string), baby_gender (type: int), second_baby_birthday (type: string), second_bady_gender (type: int), third_bady_birthday (type: string), third_bady_gender (type: int), guide_code (type: string), ori_member_id (type: string), full_name (type: string), gender (type: int), marriage_flag (type: int), birthday (type: date), subbrand_flag (type: int), province (type: string), city (type: string), area (type: string)
outputColumnNames: _col1, _col2, _col3, _col4, _col5, _col6, _col7, _col8, _col9, _col10, _col11, _col12, _col13, _col14, _col15, _col16, _col17, _col18, _col19, _col20, _col21, _col22, _col23, _col24, _col25, _col26, _col27
Statistics: Num rows: 4893285 Data size: 21217284396 Basic stats: COMPLETE Column stats: NONE
Map Join Operator
condition map:
Left Outer Join 0 to 1
keys:
0 _col4 (type: int)
1 _col0 (type: int)
outputColumnNames: _col1, _col2, _col3, _col4, _col5, _col6, _col7, _col8, _col9, _col10, _col11, _col12, _col13, _col14, _col15, _col16, _col17, _col18, _col19, _col20, _col21, _col22, _col23, _col24, _col25, _col26, _col27
Statistics: Num rows: 5382613 Data size: 23339013341 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col1 (type: bigint), _col20 (type: string), _col2 (type: string), _col3 (type: string), _col4 (type: int), _col5 (type: timestamp), _col6 (type: timestamp), _col7 (type: string), _col11 (type: timestamp), datediff(DATE'2022-08-01', _col11) (type: int), CASE WHEN ((year(_col11) = 2022)) THEN (1) ELSE (0) END (type: int), _col23 (type: date), _col21 (type: int), CASE WHEN (((2022 - year(_col23)) >= 0)) THEN ((2022 - year(_col23))) ELSE ('未知') END (type: string), _col22 (type: int), CASE WHEN ((_col22 = 0)) THEN ('未婚') WHEN ((_col22 = 1)) THEN ('已婚') ELSE ('未知') END (type: string), _col24 (type: int), _col25 (type: string), _col26 (type: string), _col27 (type: string), _col18 (type: string), _col9 (type: int), _col10 (type: timestamp), _col12 (type: string), _col13 (type: int), _col14 (type: string), _col15 (type: int), _col16 (type: string), _col17 (type: int), _col19 (type: string), _col8 (type: int), CASE WHEN ((((2022 - year(_col23)) >= 0) and ((2022 - year(_col23)) < 18))) THEN ('18岁以下') WHEN ((((2022 - year(_col23)) >= 18) and ((2022 - year(_col23)) < 26))) THEN ('18-25岁') WHEN ((((2022 - year(_col23)) >= 26) and ((2022 - year(_col23)) < 31))) THEN ('26-30岁') WHEN ((((2022 - year(_col23)) >= 31) and ((2022 - year(_col23)) < 36))) THEN ('31-35岁') WHEN ((((2022 - year(_col23)) >= 36) and ((2022 - year(_col23)) < 41))) THEN ('36-40岁') WHEN ((((2022 - year(_col23)) >= 41) and ((2022 - year(_col23)) < 46))) THEN ('41-45岁') WHEN ((((2022 - year(_col23)) >= 46) and ((2022 - year(_col23)) < 51))) THEN ('46-50岁') WHEN ((((2022 - year(_col23)) >= 51) and ((2022 - year(_col23)) < 999))) THEN ('50岁以上') ELSE ('未知') END (type: string), CASE WHEN ((((2022 - year(CAST( _col12 AS DATE))) >= 0) and ((2022 - year(CAST( _col12 AS DATE))) < 2))) THEN ('0-1岁') WHEN ((((2022 - year(CAST( _col12 AS DATE))) >= 2) and ((2022 - year(CAST( _col12 AS DATE))) < 4))) THEN ('2-3岁') WHEN ((((2022 - year(CAST( _col12 AS DATE))) >= 4) and ((2022 - year(CAST( _col12 AS DATE))) < 7))) THEN ('4-6岁') WHEN ((((2022 - year(CAST( _col12 AS DATE))) >= 7) and ((2022 - year(CAST( _col12 AS DATE))) < 11))) THEN ('7-10岁') WHEN ((((2022 - year(CAST( _col12 AS DATE))) >= 11) and ((2022 - year(CAST( _col12 AS DATE))) < 16))) THEN ('11-15岁') WHEN ((((2022 - year(CAST( _col12 AS DATE))) >= 16) and ((2022 - year(CAST( _col12 AS DATE))) < 19))) THEN ('16-18岁') WHEN ((((2022 - year(CAST( _col12 AS DATE))) >= 19) and ((2022 - year(CAST( _col12 AS DATE))) < 91))) THEN ('大于18岁') ELSE ('未知') END (type: string), CASE WHEN ((year(_col11) = 2022)) THEN ('新客') ELSE ('老客') END (type: string), '2022-07-31' (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col7, _col8, _col9, _col10, _col11, _col12, _col13, _col14, _col15, _col16, _col17, _col18, _col19, _col20, _col21, _col22, _col23, _col24, _col25, _col26, _col27, _col28, _col29, _col30, _col31, _col32, _col33, _col34
Statistics: Num rows: 5382613 Data size: 23339013341 Basic stats: COMPLETE Column stats: NONE
Limit
Number of rows: 1
Statistics: Num rows: 1 Data size: 4336 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 1 Data size: 4336 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Execution mode: vectorized
Local Work:
Map Reduce Local Work
Stage: Stage-0
Fetch Operator
limit: 1
Processor Tree:
ListSink场景,快速获取sql的结果集schema。
1=2或limit 1不能解决快速查sql schema的问题,对于涉及到join的sql,都无法快速返回。即使使用了谓词下推或将limit 1放入子查询,依然是要去数据集获取数据过滤,再执行join,依然不快。
select
`a`.`member_card_id` as `member_id`
from (select member_card_id, grade from `bi_dw`.`f_ip_hy_member_card_s` where `dt`='2022-07-31' limit 1) `a`
left join (select * from `bi_ods`.`o_my_ncm_grade_detail_f` limit 1) `b`
on `a`.`grade` = `b`.`grade_level`结果
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-5 depends on stages: Stage-1, Stage-3 , consists of Stage-6, Stage-2
Stage-6 has a backup stage: Stage-2
Stage-4 depends on stages: Stage-6
Stage-2
Stage-3 is a root stage
Stage-0 depends on stages: Stage-4, Stage-2
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: f_ip_hy_member_card_s
Statistics: Num rows: 9786571 Data size: 42434573130 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: member_card_id (type: bigint), grade (type: int)
outputColumnNames: _col0, _col1
Statistics: Num rows: 9786571 Data size: 42434573130 Basic stats: COMPLETE Column stats: NONE
Limit
Number of rows: 1
Statistics: Num rows: 1 Data size: 4336 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
sort order:
Statistics: Num rows: 1 Data size: 4336 Basic stats: COMPLETE Column stats: NONE
TopN Hash Memory Usage: 0.1
value expressions: _col0 (type: bigint), _col1 (type: int)
Execution mode: vectorized
Reduce Operator Tree:
Select Operator
expressions: VALUE._col0 (type: bigint), VALUE._col1 (type: int)
outputColumnNames: _col0, _col1
Statistics: Num rows: 1 Data size: 4336 Basic stats: COMPLETE Column stats: NONE
Limit
Number of rows: 1
Statistics: Num rows: 1 Data size: 4336 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: true
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazybinary.LazyBinarySerDe
Stage: Stage-5
Conditional Operator
Stage: Stage-6
Map Reduce Local Work
Alias -> Map Local Tables:
$INTNAME1
Fetch Operator
limit: -1
Alias -> Map Local Operator Tree:
$INTNAME1
TableScan
HashTable Sink Operator
keys:
0 _col1 (type: int)
1 _col0 (type: int)
Stage: Stage-4
Map Reduce
Map Operator Tree:
TableScan
Map Join Operator
condition map:
Left Outer Join 0 to 1
keys:
0 _col1 (type: int)
1 _col0 (type: int)
outputColumnNames: _col0
Statistics: Num rows: 1 Data size: 4769 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 1 Data size: 4769 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Execution mode: vectorized
Local Work:
Map Reduce Local Work
Stage: Stage-2
Map Reduce
Map Operator Tree:
TableScan
Reduce Output Operator
key expressions: _col1 (type: int)
sort order: +
Map-reduce partition columns: _col1 (type: int)
Statistics: Num rows: 1 Data size: 4336 Basic stats: COMPLETE Column stats: NONE
value expressions: _col0 (type: bigint)
TableScan
Reduce Output Operator
key expressions: _col0 (type: int)
sort order: +
Map-reduce partition columns: _col0 (type: int)
Statistics: Num rows: 1 Data size: 810 Basic stats: COMPLETE Column stats: NONE
Reduce Operator Tree:
Join Operator
condition map:
Left Outer Join 0 to 1
keys:
0 _col1 (type: int)
1 _col0 (type: int)
outputColumnNames: _col0
Statistics: Num rows: 1 Data size: 4769 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 1 Data size: 4769 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-3
Map Reduce
Map Operator Tree:
TableScan
alias: o_my_ncm_grade_detail_f
Statistics: Num rows: 8492 Data size: 6884400 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: grade_level (type: int)
outputColumnNames: _col0
Statistics: Num rows: 8492 Data size: 6884400 Basic stats: COMPLETE Column stats: NONE
Limit
Number of rows: 1
Statistics: Num rows: 1 Data size: 810 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
sort order:
Statistics: Num rows: 1 Data size: 810 Basic stats: COMPLETE Column stats: NONE
TopN Hash Memory Usage: 0.1
value expressions: _col0 (type: int)
Execution mode: vectorized
Reduce Operator Tree:
Select Operator
expressions: VALUE._col0 (type: int)
outputColumnNames: _col0
Statistics: Num rows: 1 Data size: 810 Basic stats: COMPLETE Column stats: NONE
Limit
Number of rows: 1
Statistics: Num rows: 1 Data size: 810 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: true
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazybinary.LazyBinarySerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
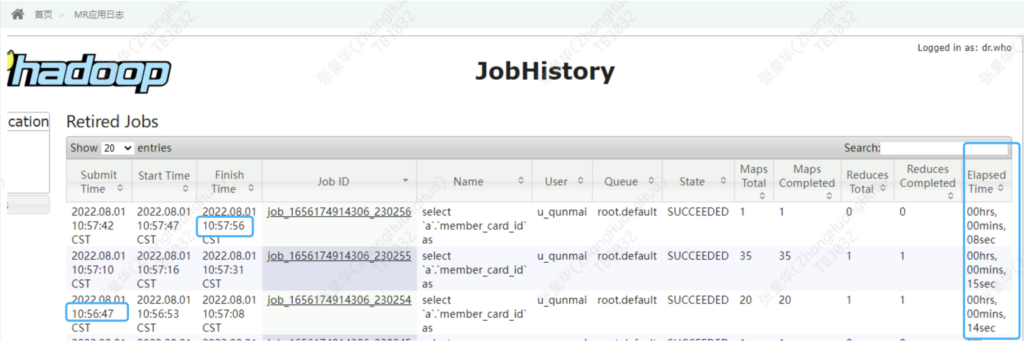
ListSink看具体执行截图
dbeaver client提交耗时71秒
看看具体耗时在哪
Mr: 69秒
关于hiveserver2谓词下推的资料:

No Comments
Leave a comment Cancel