









why schema?
引用Jay kreps的话,关于topic的schema。原文见《Why Avro for Kafka Data?》。
one thing you’ll need to do is pick a data format. The most important thing to do is be consistent across your usage。
- json虽然表达能力强,但冗余,尤其对于kafka这类数据存储。
- 引入序列化协议及schema注册中心,可以优化数据存储、支持schema evolve,保证生产消费对同个字段的相同解析,简化etl处理。
- 但也有折衷,引入注册中心无于多了组件,如果registry宕机,kafka 不可用。所以很多公司不会使用json,而是使用自已约定的消息格式,除非像一些传统公司技术能力欠缺或者kafka消息体量很小还不考虑吞吐和性能问题,当然也有可能公司不差钱。
confluent官方提供了schema registry,用于schema的注册等级,生产消费都会从它那里登记或获取消息序列反序列化schema。
官方支持的schema类型有avro,json,protobuf,推荐avro,原因见上面的链接,摘要如下
We chose Avro as a schema representation language after evaluating all the common options—JSON, XML, Thrift, protocol buffers, etc. We recommend it because it is the best thought-out of these for this purpose. It has a pure JSON representation for readability but also a binary representation for efficient storage. It has an exact compatibility model that enables the kind of compatibility checks described above. It’s data model maps well to Hadoop data formats and Hive as well as to other data systems. It also has bindings to all the common programming languages which makes it convenient to use programmatically.
当然也有成本。
confluent对schema registry的license是部分community license,部分enterprise license,如validation。
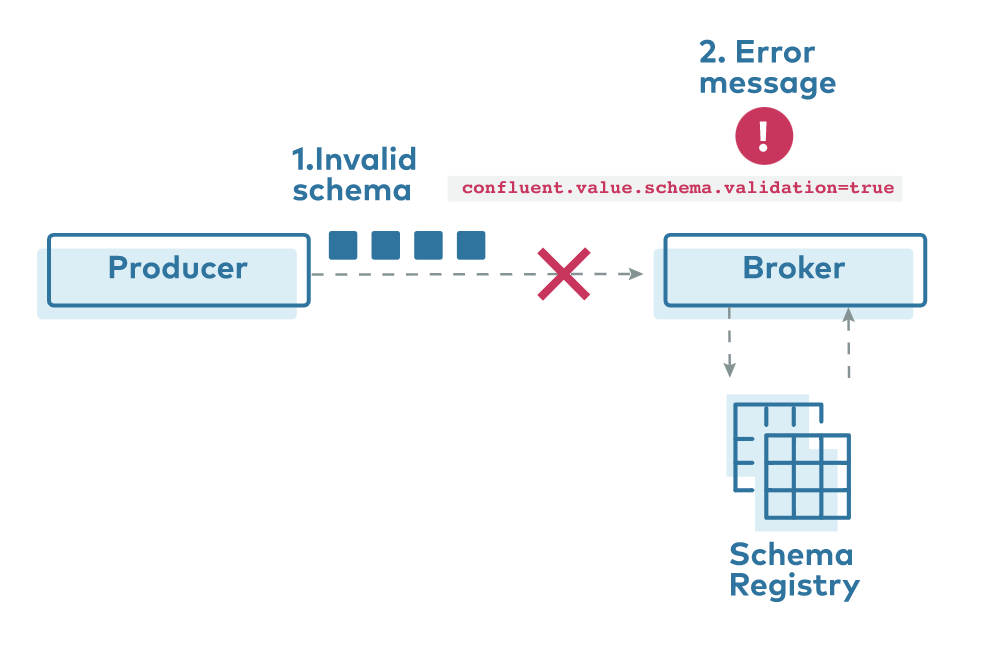
具体licence见:https://docs.confluent.io/platform/current/installation/license.html
how or when to use?
Don’t do it.
如果只是做数据探索,可以参考schema registry的源码自定义,行为数据不用过于追求schema。cdc数据可以考虑debezium的schema如何实现。
参考:
https://www.confluent.io/product/confluent-platform/data-compatibility/
https://docs.confluent.io/platform/current/schema-registry/index.html#schemaregistry-intro
https://medium.com/slalom-technology/introduction-to-schema-registry-in-kafka-915ccf06b902

No Comments
Leave a comment Cancel