








When it comes to the problem of high disk io on yarn cluster, it may lead to many undesirable situations, such as application’s slowing down too much, hdfs operation shows high latency, although the file being operated is very small.
What happened?
It may be a shuffle problem. For example, spark is our main compute engine, we can add some spark listeners to collect spark stage metrics, and for analysis, we log it to elastic search.
class SparkLogEventTracker() extends SparkListener with QueryExecutionListener with Logging {
override def onApplicationStart(e: SparkListenerApplicationStart): Unit = {
//...
}
override def onApplicationEnd(e: SparkListenerApplicationEnd): Unit = {
val event = BeanUtils.cloneBean(APP_START_EVENT).asInstanceOf[SparkLogEvent]
event.setAction("app-end")
event.setAppEndTime(e.time)
val sql = StringUtils.join(StatCollector.getLogicalPlan2sql().values(), "\n;\n")
event.setSql(sql)
event.setTables(StatCollector.getTablesAsList())
event.setUpdateTime(System.currentTimeMillis())
audit(event)
// wait before log to report to es
EXEC_POOL.awaitTermination(30, TimeUnit.SECONDS)
}
override def onSuccess(funcName: String, qe: QueryExecution, durationNs: Long): Unit = {
val event = BeanUtils.cloneBean(APP_START_EVENT).asInstanceOf[SparkLogEvent]
event.setAction("query-" + funcName)
event.setSql(StatCollector.getLogicalPlan2sql().get(qe.logical))
event.setQueryExecution(qe)
event.setExecDuration(TimeUnit.NANOSECONDS.toMillis(durationNs))
/*if (qe != null) {
event.setSqlExplain(qe.toString())
}*/
event.setUpdateTime(System.currentTimeMillis())
audit(event)
}
def audit(event: SparkLogEvent): Unit = {
EXEC_POOL.submit(new Runnable() {
// run log report async
override def run(): Unit = {
val eq = event.getQueryExecution
if (eq != null && eq.executedPlan != null) {
// update metric info
/*if (eq.executedPlan.metrics != null && eq.executedPlan.metrics.nonEmpty) {
for ((key, value) <- eq.executedPlan.metrics) {
val metric = new SqlMetric
metric.setName(key)
metric.setType(value.metricType)
metric.setValue(value.value)
event.getMetrics.add(metric)
}
}*/
}
if ("app-end".equals(event.getAction())) {
event.setAccumulableMetric(STAGE_METRIC)
EsLogClient.log(event)
}
}
})
}
override def onStageCompleted(stageCompleted: SparkListenerStageCompleted): Unit = {
// accumulate stage metric totally
try {
for ((key, accumulableInfo) <- stageCompleted.stageInfo.accumulables) {
val value = STAGE_METRIC.getOrDefault(accumulableInfo.name.get, 0L)
STAGE_METRIC.put(accumulableInfo.name.get, value + accumulableInfo.value.get.asInstanceOf[Long])
}
} catch {
case e: Throwable => log.warn(e.getMessage, e)
}
}
}It turn outs to be that some apps shuffled TB of files. How to alleviate this problem?
In the short term, we can optimize the app codes to read or write less files. In the long term, We should pay attention to the shuffle service on yarn.
The term shuffle is used to refer to the exchange of data between multiple computational units. Spark uses this term when data has to be reorganized amongst its executors.
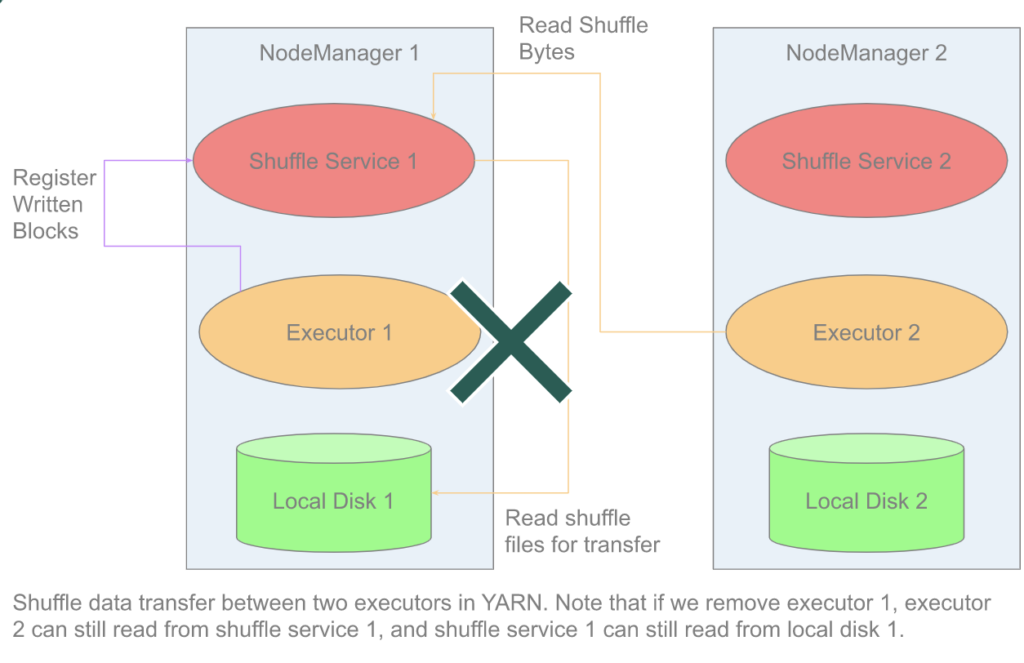
please refer to this doc to see the detail of spark shuffle, including weakness and new design objects.
After that, we can add a separated and independant shuffle service to improve availability and scalability of the shuffle service, such as uber rss or celeborn (from alibaba) or apache uniffle (from tencent)

No Comments
Leave a comment Cancel