








大数据平台,有一类需求,需要验证sql的正确性。你能想到几种方式?
1、单纯的用antlr生成AST是否足够?答案是对于和hive表相关的验证是否定的。就像spark sql的执行过程,逻辑执行计划 到 物理执行计划,需要结合source schema添加列信息。所以直接用工具生成AST还不够。
2、使用hiveserver2 执行一段sql?举例验证concat(field, field1) as new_field这个sql是否正确。可以生成一个sql=’select ${to_verify_pattern} from hive_table limit 0’。这种方式部分可行,由于没有发生agg聚合,hiveserver不需要生成mr任务,直接拿一个新的分区获取数据即可。但如果是要验证数据模型是否正确,例如有相关的join操作,则这种方式会生成mr任务。hiveserver2对mr也快废弃了,可以替换成tez会快一些。更快的方式?在sql前加个explain,使用explain的方式一起把语法和schema都检查了,还不用生成实际执行任务。
3、使用spark?向“在线spark常驻进程”发送sql,对方将执行结果写到redis,客户端从redis获取结果集。主要的优势是常驻进程内存迭代,运算快也没有mr的启动时间。但也有劣势,from xxx表之后如果没有where partition限定条件,spark没法像hive那样决定读哪些文件即可,所以它会把全量文件都读取进来,再做数据过滤或运算,所以不一定会更快,看自己的场景需求。
关于spark sql的谓词下推、列裁剪等,详见:https://www.hnbian.cn/posts/7049ff8.html
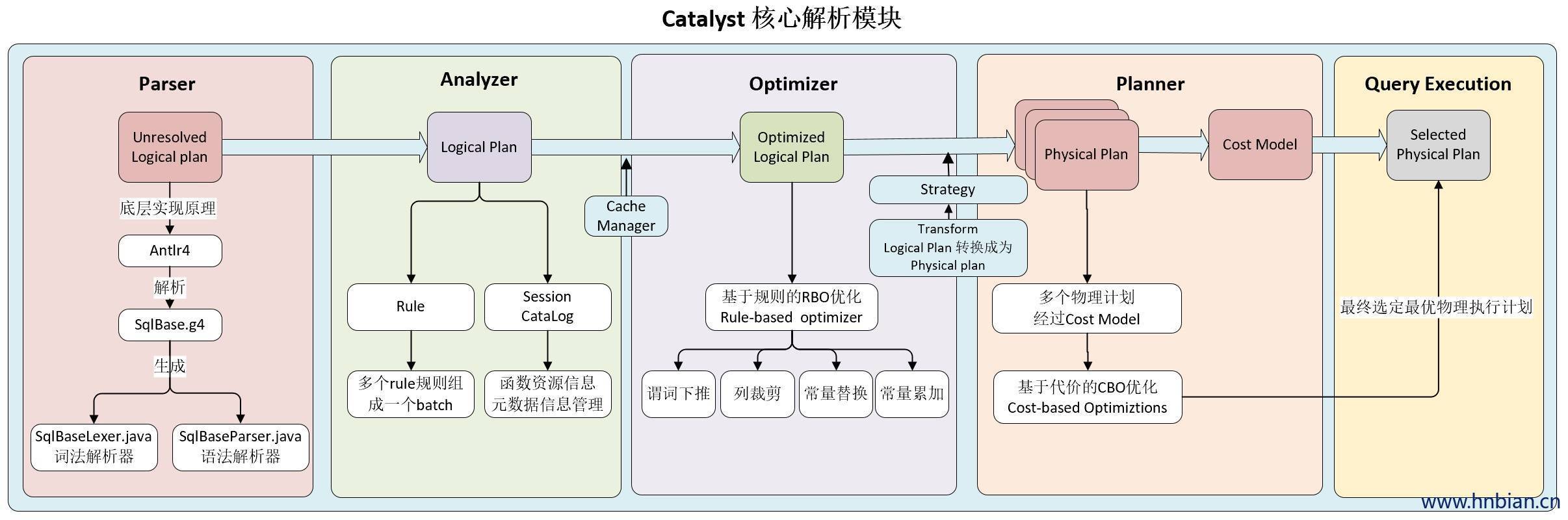
ColumnPruning 列裁剪可以把那些查询不需要的字段过滤掉,使得扫描的数据量减少。
PushDownPredicate 将 Filter 算子直接下推到 Join 之前。
扩展:trino的pushdown

No Comments
Leave a comment Cancel