








事件:
datax on yarn 3点出现任务失败,错误信息:[Error] DataX receive unexpected signal 15, starts to suicide。jdk还打印了stack信息。
问题分析:
signal15为外部kill,jvm打印thread dump也是由于kill产生,尤其是kill -3会thread dump。
是机器内存不足被OS kill?
到/var/log/messages寻找,无相关日志,机器内存监控显示内存充足。
yarn资源抢占,被yarn rm kill了?
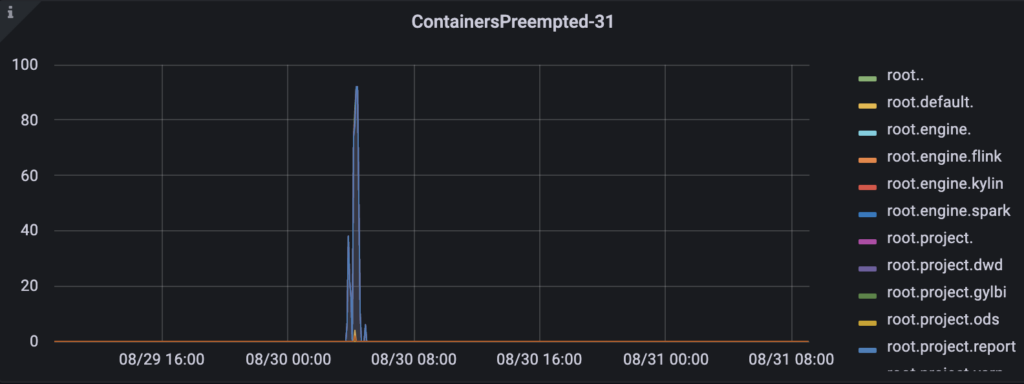
集群使用fair + drf调度策略,并开启了资源抢占。不同的队列之间资源会相互竞争和抢占。定位问题,寻找rm的日志,找到对应container被kill的日志。
cat hadoop-admin-resourcemanager-atbgmaster01.log | grep Preemp
2022-08-30 03:46:45,405 INFO org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FSPreemptionThread: Preempting container container_e218_1660283393121_113037_01_000002 from queue: root.project.yarn
2022-08-30 03:47:00,405 INFO org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FSPreemptionThread: Killing container container_e218_1660283393121_113037_01_000002添加yarn抢占容器数量监控
Hadoop_ResourceManager_AggregateContainersPreempted{name=”QueueMetrics”,q0=”root”, user=””,instance=”x.x.x.x:7011″}
解决方式:
1、队列划分更精细,资源划分按业务,调整配比
2、关闭资源抢占
原理:
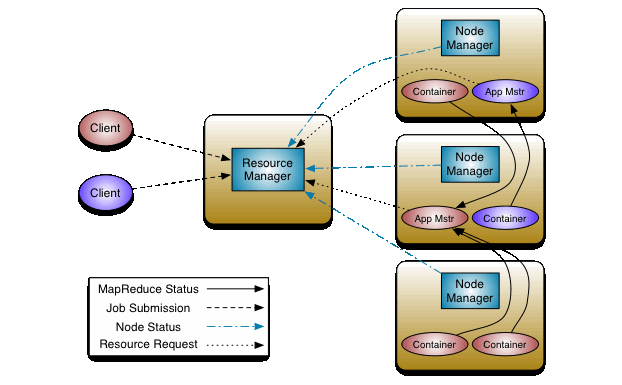
FIFO Scheduler、Capacity Scheduler、Fair Scheduler
什么时候发生抢占?
Ø 最小资源抢占, 当前queue的资源无法保障时,而又有apps运行,需要向外抢占。
Ø 公平调度抢占, 当前queue的资源为达到max,而又有apps运行,需要向外抢占。
具体详见yarn源码实现。
参考:
https://cloud.tencent.com/developer/article/1195056 YARN资源调度策略

No Comments
Leave a comment Cancel